
Actualmente hablar de Minería de Datos en congresos y conferencias llama mucho la atención, y no es para sorprender ya que estamos viviendo en una era en donde la tecnología y el Internet nos ha permitido generar y recopilar grandes volúmenes de información. Generamos información en redes sociales, en los bancos, en las tiendas departamentales, en el cine, hospitales y más. Para las empresas u organizaciones los datos son materia prima para poder encontrar patrones que favorezcan a interpretar fenómenos o sucesos, por ejemplo qué gustos tiene un usuario, saber si un cuentahabiente se le puede otorgar un préstamo, qué producto se vende más según temporadas, cuál es el perfil de personas que ven una determinada película, o cuáles son las causas de una enfermedad.
Muchas personas que empiezan a explorar el área confunden que este concepto es Minería de Datos, sin embargo no es así. La Minería de Datos en realidad es el núcleo de todo un proceso llamado Descubrimiento de Conocimiento en Base de Datos (Knowledge Discovery in Databases – KDD) (ver fig. 1), el cual es un proceso metodológico para encontrar un “modelo” válido, útil y entendible que describa patrones de acuerdo a la información, y como modelo entendemos que es la representación que intenta explicar ese patrón en los datos. Es importante mencionar que hablar de “modelo” como fórmula mágica no significa que existe una maestra para cualquier problemática, sino todo lo contrario, pues existen muchos métodos o algoritmos que podrían satisfacer las necesidades dependiendo de los objetivos del estudio y de los datos que se quieran analizar. Es por esta razón que un requisito para poder adentrarse en esta área es tener conocimiento de conceptos de Estadística.
{kind=link}
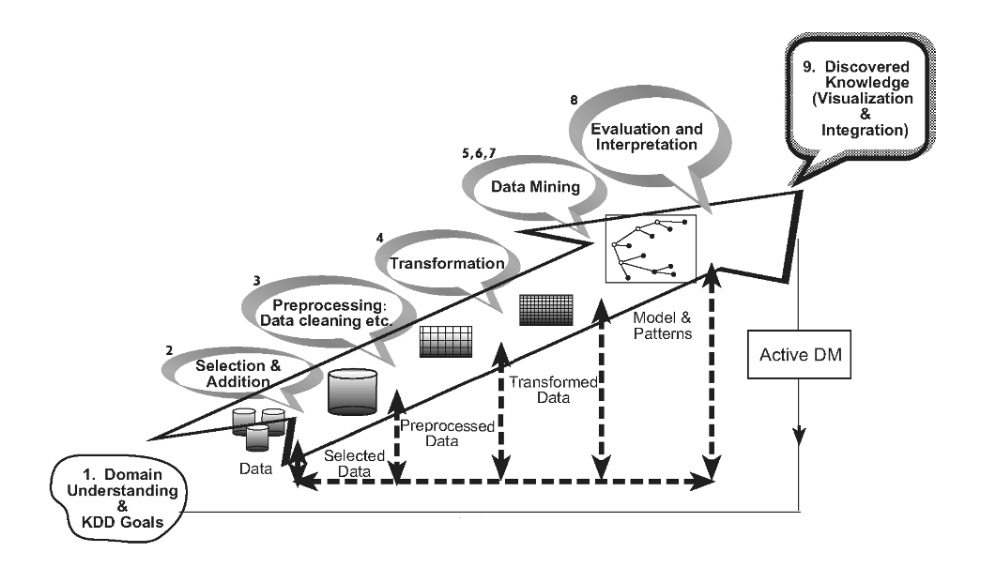
En esta publicación me daré a la tarea de explicar brevemente el proceso de KDD en cada uno de sus pasos para tener conciencia de esta metodología y tener claro qué es la Minería de Datos y donde está ubicada. Como mencioné antes, KDD es un proceso metodológico y además secuencial que se sigue para encontrar conocimiento en un conjunto de datos en bruto. Estos pasos se dividen en 9 que son: 1) abstracción del escenario, 2) selección de datos, 3) limpieza y pre-procesamiento, 4) transformación de los datos, 5) elección de tareas de Minería de Datos, 6) elección del algoritmo, 7) aplicación del algoritmo, 8) evaluación e interpretación y 9) entendimiento del conocimiento.
Antes de esto definamos un conjunto de datos, el cual es una colección de información, ya sea cuantitativa o cualitativa y que está compuesto por variables o atributos (columnas) que representan las propiedades de un fenómeno o suceso, y casos (filas) que significan los diferentes sucesos que se presentaron en el escenario. Esto constituye es la materia prima del KDD. Ahora, aquí sus fases:
1 – Abstracción del escenario
No todo es matemática y estadística, sino entender la problemática a la que nos vamos a enfrentar y tener contexto para proponer soluciones viables y reales, ya que me ha tocado ver propuestas absurdas. Es importante conocer las propiedades, limitaciones y reglas del escenario en estudio, para posteriormente definir las metas a alcanzar.
2 – Selección de los datos
Del conjunto de datos recolectados y ya definidos los objetivos por alcanzar, se deben elegir datos disponibles para realizar el estudio e integrarlos en uno solo que puedan favorecer a llegar a alcanzar a los objetivos del análisis. Muchas veces esta información puede encontrarse en una misma fuente (centralizado) o pueden estar distribuidos.
3 – Limpieza y pre-procesamiento
En esta etapa se determina la confiabilidad de la información, es decir, realizar tareas que garanticen la utilidad de los datos. Para esto se hace la limpieza de datos (tratamiento de datos perdidos o remover valores atípicos). Esto implica eliminar variables o atributos con datos faltantes o eliminar información no útil para este tipo de tareas como el texto (aunque puede utilizarse para hacer Minería de Texto, que es otro asunto).
4 – Transformación de los datos
En esta etapa se mejora la calidad de los datos con transformaciones que involucran ya sea reducción de dimensionalidad (disminuir la cantidad de variables del conjunto de datos) o bien transformaciones como por ejemplo convertir los valores que son números a categóricos (discretización).
5 – Selección de la apropiada tarea de Minería de Datos
Fase en la que se refiere a elegir el paradigma apropiado de Minería de Datos, ya sea la clasificación, regresión o agrupación, según los objetivos que se haya planteado para la investigación (predicción o descripción), la primera ocupada para encontrar un modelo que sea utilizada para casos futuros y desconocidos; mientras que la segunda solo para observar su comportamiento.
6 – Elección del algoritmo de Minería de Datos
Posteriormente se procede a seleccionar la técnica o algoritmo, o incluso más de uno para la búsqueda del patrón y obtener conocimiento. El meta-aprendizaje se enfoca en explicar la razón por la que un algoritmo funciona mejor en determinadas problemáticas, y para cada técnica existen diferentes posibilidades de cómo seleccionarlas. Cada algoritmo tiene su propia esencia, su propia manera de trabajar y obtener los resultados, por lo que es recomendable conocer las propiedades de aquellos candidatos a utilizar y ver cual se ajusta mejor a los datos. En 2015 se publicó un artículo que intenta abordar justamente este problema, realizando una comparación entre diferentes clasificadores en distintas problemáticas. Puedes verlo dando clic aquí.
7 – Aplicación del algoritmo
Por fin, una vez seleccionado las técnicas el paso siguiente es aplicarlo a los datos ya seleccionados, limpiados y procesados. Es posible que la ejecución de los algoritmos sean varias intentando ajustar los parámetros que optimicen los resultados. Estos parámetros varían de acuerdo al método seleccionado.
8 – Evaluación
Una vez aplicado los algoritmos al conjunto de datos, procedemos a evaluar los patrones que se generaron y el rendimiento que se obtuvo para verificar que cumpla con las metas planteadas en las primeras fases. Para realizar esta evaluación existe una técnica que se llama Validación Cruzada (también abordado en el artículo anterior), el cual realiza una partición de los datos dividiéndose en entrenamiento (que servirán para crear el modelo) y prueba (que serán utilizados para ver que en verdad funciona el algoritmo y realiza su trabajo bien).
9 – Aplicación
Si todos los pasos se siguen correctamente y los resultados de la evaluación se satisfacen, la última etapa es simplemente aplicar el conocimiento encontrado al contexto y comenzar a resolver sus problemáticas. Si de lo contrario, los resultados no son satisfactorios entonces es necesario regresar a las anteriores etapas a realizar algún ajuste, analizando desde la selección de los datos hasta en la etapa de evaluación.
La Minería de Datos, en conclusión, no es más que un segmento de fases dentro del proceso de KDD, que abarcan los puntos 5, 6 y 7, donde se realizan las tareas nucleares de esta metodología. Sin embargo cada una de las fases mencionadas tiene su complejidad y especialidad, teniendo un amplio campo de estudio, pero sin duda un una gran cantidad de aplicaciones. Hablar de Minería de Datos implica familiarización de las matemáticas y no solamente de aplicarlas, sino entenderlas, pues hasta un promedio tiene un gran significado. La información varía mucho tanto de la fuente como del contexto, por lo que hablar de la selección del “algoritmo de maestro” o el “modelo de oro” para resolver cualquier problema sería una irresponsabilidad afirmarlo, y para esto se requiere de un análisis previo, realizando estadística descriptiva por ejemplo. Si estás interesado en adentrarte a este mundo, la recomendación primordial es comienza a tomar gusto por las matemáticas y todas las fórmulas que alguna vez odiaste, ya que las verás mucho.
[1] Oded Maimon and Lior Rokach. 2005. Data Mining and Knowledge Discovery Handbook. Springer-Verlag New York, Inc., Secaucus, NJ, USA.
Muchas gracias por el artículo. Hoy tengo que rendir Big Data para la universidad y me aclaraste las dudas que tenía sobre el KDD. Saludos!!
Hola
Excelente articulo. Muchas gracias.
no se
una consulta, para una empresa,cuantas veces debería de aplicarse esta técnica o con que tanta frecuencia?
Muchas gracias, muy claro.